Data Science Course In Pimpri Chinchwad
Hey! Give Proper Way to Your Career by Learning and Completing Data Science Course In Pimpri Chinchwad.
This course is perfectly designed with a practical, theoretical, and industry-oriented training module to help you achieve your goals with a data science course.
Recruiters will find you with your certification and what you learned in this all-data science course, that’s it.
Course Path
-
Database SQL
-
Advanced Excel
-
Python Programming
-
R Programming
-
Power BI
-
Tableau
-
Machine learning
-
Artificial Intelligence & Deep Learning
-
NLP
Enquire Now
15214
Students Enrolled
4.8
Google Reviews
Guaranteed
Job Interviews
6 Months
Duration
250+ Hours
of Learning

What is Data Science?
Data science, in its most basic terms, can be defined as obtaining insights and information, really anything of value, out of data.
It can also be defined as a combination of algorithms, data research, and technology to solve complex analytical issues.
Much to learn by mining it. Advanced capabilities we can build with it. It’s Big analytical creativity which only performs on the basis of data Science.
This process involves collecting clean data subsets and inserting suitable defaults, and it also has some more complex methods like identifying missing values by modeling, and something like that.
Once the data cleaning is done, the next step is to integrate and create a conclusion from the dataset for analysis.
Why Should I take Data Science Course In Pimpri Chinchwad?
We are analytiq Learning Provides you Data Science Course In Pimpri Chinchwad with practical orientation of training. Live project based training having both the facilities i.e online and classroom training.
We are only the institute who provide you a 100% job placement assistance. we have data science certification which is really important for job interviews.
A good Placement team will assist you about your requirements of job and if you need any help regarding placement then our team will help you unconditionallly.
we have labs for practical experimentation of what you learn everyday. You can practice your daily work there.

Who can do Data Science Classes?
- Fresher’s BE/ Bsc Candidate
- Any Engineers
- Any Graduate
- Any Post-Graduate
- Working Professionals
- Professionals from KPO,BPO, Tech Support, Back Office.
Our Alumni Works at






Batches We Offer for Data Science Classes In Pimpri Chinchwad
Fast Track Batch
- Session: 4 Hrs per day + Practical
- Duration: 1.5 Months
- Certification: Yes
- Training Type: Classroom
- Study Material: Latest Book
- Days: Monday to Friday
- Practical & Labs: Regular
- Personal Grooming: Flexible Time
Regular Batch
- Session: 1.5 Hrs per day
- Duration: 2 Months
- Certification: Yes
- Training Type: Classroom
- Study Material: Latest Book
- Days: Monday to Friday
- Practical & Labs: Regular
- Personal Grooming: Flexible Time
Weekend Batch
- Session: 2.5 Hrs per day
- Duration: 2.5 Months
- Certification: Yes
- Training Type: Classroom
- Study Material: Latest Book
- Days: Saturday & Sunday
- Practical & Labs: As Per Course
- Personal Grooming: Flexible Time
Upcoming Batch Schedule for Data Science Classes in Pimpri-Chinchwad
| Sr.No | Date | Duration | Batch | Training Type | Time |
|---|---|---|---|---|---|
|
1 |
10-06-2025 |
3 – 6 Months |
Regular (Mon-Sat) |
Online/Offline |
10-1Pm / 11:30-2:30Pm / 1-4Pm
|
|
2 |
17-06-2025 |
3 – 6 Months |
Regular (Mon-Sat) |
Online/Offline |
10-1Pm / 11:30-2:30Pm / 1-4Pm
|
|
3 |
24-06-2025 |
3 – 6 Months |
Regular (Mon-Sat) |
Online/Offline |
10-1Pm / 11:30-2:30Pm / 1-4Pm
|
|
4 |
01-07-2025 |
3 – 6 Months |
Regular (Mon-Sat) |
Online/Offline |
10-1Pm / 11:30-2:30Pm / 1-4Pm
|
|
5 |
08-07-2025 |
3 – 6 Months |
Regular (Mon-Sat) |
Online/Offline |
10-1Pm / 11:30-2:30Pm / 1-4Pm
|
key feature of our Data Science Classes In Pimpri Chinchwad is as below
Practiacal Based Labs with Advance Computers
All Smart Amenities like Projector etc.
Online/ Classroom Training facilities
Interview/ Mock Test Preparation
Multiple and Flexible Batches
Course Material Available
Trainer Profile of Data Science Course In Pimpri Chinchwad
Our Trainers provide complete freedom to the students, to explore the subject and learn based on real-time examples.
Our trainers help the candidates in completing their projects and even prepare them for interview questions and answers.
Candidates are free to ask any questions at any time.
-
More than 10+ Years of Experience.
-
Trained more than 2000+ students in a year.
-
Strong Theoretical & Practical Knowledge.
-
Certified Professionals with High Grade.
-
Well connected with Hiring HRs in multinational companies.
-
Expert level Subject Knowledge and fully up-to-date on real-world industry applications.
-
Trainers have Experienced on multiple real-time projects in their Industries.
Career Opportunities
Freshers/ Professional Job Opening for Data Science Training in PCMC
Where a professional can get a Job

Data Scientist

Data Engineer

Algorithm Specialist

DevOps Engineer
Data Analyst

Senior Software Engineer
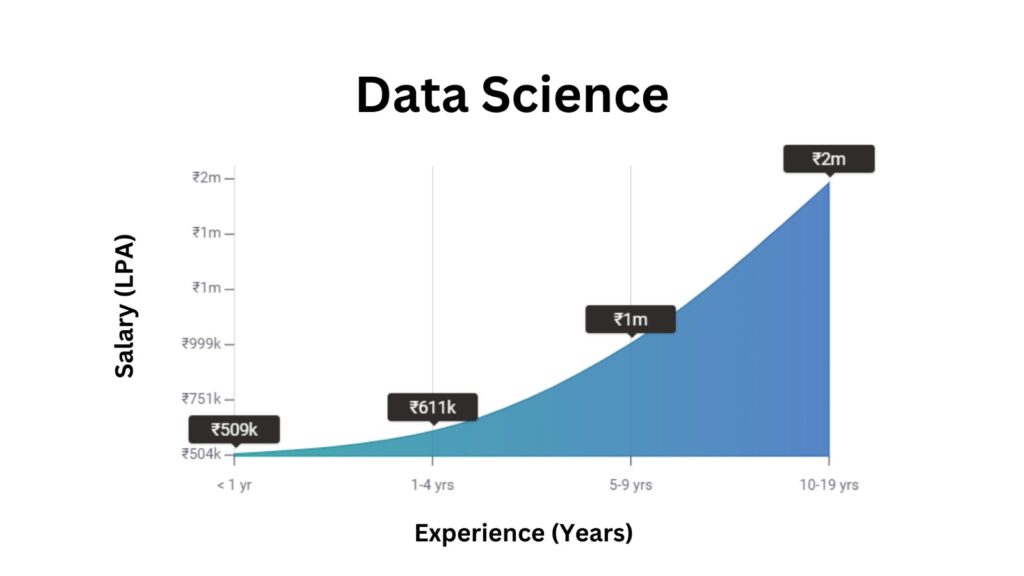
Career Progression and Salary Trends
Course Completion Certificate

Syllabus Of Data Science Classes In Pimpri Chinchwad
- Types of Variable
- Types of Datatype
- Types of Modifiers
- Types of constructors
- Introduction to OOPS concept
- Types of OOPS concept
- Introduction to Java Server Pages
- Introduction to Servlet
- Introduction to Java Database Connectivity
- How to create Login Page
- How to create Register Page
- Introduction to Big Data
- Characteristics of Big Data
- Big data examples
- BigData Inroduction,Hadoop Introduction and HDFS Introduction
- Hadoop Architecture
- Installing Ubuntu with Java on VM Workstation 11
- Hadoop Versioning and Configuration
- Single Node Hadoop installation on Ubuntu
- Multi Node Hadoop installation on Ubuntu
- Hadoop commands
- Cluster architecture and block placement
- Modes in Hadoop
– Local Mode
– Pseudo Distributed Mode
– Fully Distributed Mode - Hadoop components
– Master components(Name Node, Secondary Name Node, Job Tracker)
– Slave components(Job tracker, Task tracker) - Task Instance
- Hadoop HDFS Commands
- HDFS Access-Java Approach
- MapReduce Introduction
- Understanding Map Reduce Framework
- What is MapReduceBase?
- Mapper Class and its Methods
- What is Partitioner and types
- Relationship between Input Splits and HDFS Blocks
- MapReduce: Combiner & Partitioner
- Hadoop specific Data types
- Working on Unstructured Data Analytics
- Types of Mappers and Reducers
- WordCount Example
- Developing Map-Reduce Program using Eclipse
- Analysing dataset using Map-Reduce
- Running Map-Reduce in Local Mode.
- MapReduce Internals -1 (In Detail) :
– How MapReduce Works
– Anatomy of MapReduce Job (MR-1)
– Submission & Initialization of MapReduce Job (What Happen ?)
– Assigning & Execution of Tasks
– Monitoring & Progress of MapReduce Job
– Completion of Job
– Handling of MapReduce Job
– Task Failure
– TaskTracker Failure
– JobTracker Failure - Advanced Topic for MapReduce (Performance and Optimization) :
– Job Sceduling
– In Depth Shuffle and Sorting - Speculative Execution
- Output Committers
- JVM Reuse in MR1
- Configuration and Performance Tuning
- Advanced MapReduce Algorithm :
- File Based Data Structure
– Sequence File
– MapFile - Default Sorting In MapReduce
– Data Filtering (Map-only jobs)
– Partial Sorting - Data Lookup Stratgies
– In MapFiles - Sorting Algorithm
– Total Sort (Globally Sorted Data)
– InputSampler
– Secondary Sort - MapReduce DataTypes and Formats :
- Serialization In Hadoop
- Hadoop Writable and Comparable
- Hadoop RawComparator and Custom Writable
- MapReduce Types and Formats
- Understand Difference Between Block and InputSplit
Role of RecordReader
FileInputFormat
ComineFileInputFormat and Processing whole file Single
MapperEach input File as a record
Text/KeyValue/NLine InputFormat
BinaryInput processing
MultipleInputs Format
DatabaseInput and Output
Text/Biinary/Multiple/Lazy OutputFormat MapReduce Types
TOOLS:
Apache Sqoop
– Sqoop Tutorial
– How does Sqoop Work
– Sqoop JDBCDriver and Connectors
– Sqoop Importing Data
– Various Options to Import Data
– Table Import
– Binary Data Import
– SpeedUp the Import
– Filtering Import
– Full DataBase Import Introduction to SqoopeApache Hive
-What is Hive ?
– Architecture of Hive
– Hive Services
– Hive Clients
– How Hive Differs from Traditional RDBMS
– Introduction to HiveQL
– Data Types and File Formats in Hive
– File Encoding
– Common problems while working with Hive
– Introduction to HiveQL
– Managed and External Tables
– Understand Storage Formats
– Querying Data– Joins, SubQueries and Views
– Writing User Defined Functions (UDFs)
– Data types and schemas
– Querying Data
– HiveODBC
– User-Defined FunctionsApache Pig :
– What is Pig ?
– Introduction to Pig Data Flow Engine
– Pig and MapReduce in Detail
– When should Pig Used ?
– Pig and Hadoop Cluster
– Pig Interpreter and MapReduce
– Pig Relations and Data Types
– PigLatin Example in Detail
– Debugging and Generating Example in Apache PigHBase:
– Fundamentals of HBase
– Usage Scenerio of HBase
– Use of HBase in Search Engine
– HBase DataModel
– Table and Row
– Column Family and Column Qualifier
– Cell and its Versioning
– Regions and Region Server
– HBase Designing Tables
– HBase Data Coordinates
– Versions and HBase Operation
– Get/Scan
– Put
– DeleteApache Flume:
– Flume Architecture
-Installation of Flume
-Apache Flume Dataflow
-Apache Flume Environment
-Fetching Twitter DataApache Kafka:
-Introduction to Kafka
-Cluster Architecture
-Installation of kafka
-Work Flow
-Basic Operations
-Real time application(Twitter)HADOOP ADMIN:
-Introduction to Big Data and Hadoop
-Types Of Data
-Characteristics Of Big Data
-Hadoop And Traditional Rdbms
-Hadoop Core Services
-Hadoop single node cluster(HADOOP-1.2.1)
-Tools installation for hadoop1x.
-Sqoop,Hive,Pig,Hbase,Zookeeper.
-Analyze the cluster using
a)NameNode UI
b)JobTracker UI
-SettingUp Replication Factor
-Introduction to Hadoop Distributed File System
-Goals of HDFS
-HDFS Architecture
-Design of HDFS
-Hadoop Storage Mechanism
-Measures of Capacity Execution
-HDFS Commands
Hadoop single node Cluster Setup for 1X series :
Hadoop Distributed File System:
www.sevenmentor.com
-Understanding MapReduce
-The Map and Reduce Phase
-WordCount in MapReduce
-Running MapReduce Job
-WordCount in MapReduce
-Running MapReduce Job
The MapReduce Framework:
-Hadoop single node cluster(HADOOP-2.7.3)
-Tools installation for hadoop2x
-Sqoop,Hive,Pig,Hbase,Zookeeper.
Hadoop single node Cluster Setup :
-Hadoop single node cluster(HADOOP-2.7.3)
-Tools installation for hadoop2x
-Sqoop,Hive,Pig,Hbase,Zookeeper.
Hadoop single node Cluster Setup :
-Introduction to YARN
-Need for YARN
-YARN Architecture
-YARN Installation and Configuration
Yarn:
-hadoop multinode cluster
-Checking HDFS Status
-Breaking the cluster
-Copying Data Between Clusters
-Adding and Removing Cluster Nodes
-Name Node Metadata Backup
-Cluster Upgrading
Hadoop Multinode cluster setup:-Sqoop
-Hive
-Pig
-HBase
-zookeeper
Hadoop ecosystem:
- Introduction to scala
- Programming writing Modes
i.e. Interactive Mode,Script Mode - Types of Variable
- Types of Datatype
- Function Declaration
- OOPS concepts
- Introduction to Spark
- Spark Installation
- Spark Architecture
- Spark SQL
– Dataframes: RDDs + Tables
– Dataframes and Spark SQL - Spark Streaming
– Introduction to streaming
– Implement stream processing in Spark using Dstreams
-Stateful transformations using sliding windows - Introduction to Machine Learning
- Introduction to Graphx
-Sqoop
-Hive
-Pig
-HBase
-zookeeper
Hadoop ecosystem:
- Introduction to Python
– What is Python and history of Python?
– Unique features of Python
– Python-2 and Python-3 differences
– Install Python and Environment Setup
– First Python Program
– Python Identifiers, Keywords and Indentation
– Comments and document interlude in Python
– Command line arguments
– Getting User Input
– Python Data Types
– What are variables?
– Python Core objects and Functions
– Number and Maths
– Week 1 Assignments - List, Ranges & Tuples in Python
– Introduction
– Lists in Python
– More About Lists
– Understanding Iterators
– Generators , Comprehensions and Lambda Expressions
– Introduction
– Generators and Yield
– Next and Ranges
– Understanding and using Ranges
– More About Ranges
– Ordered Sets with tuples - Python Dictionaries and Sets
-Introduction to the section
– Python Dictionaries
– More on Dictionaries
– Sets
– Python Sets Examples - Python built in function
-Python user defined functions
-Python packages functions
-Defining and calling Function
-The anonymous Functions
– Loops and statement in Python
-Python Modules & Packages - Python Object Oriented
– Overview of OOP
– Creating Classes and Objects
– Accessing attributes
– Built-In Class Attributes
– Destroying Objects - Python Object Oriented
– Overview of OOP
– Creating Classes and Objects
– Accessing attributes
– Built-In Class Attributes
– Destroying Objects
- Python Exceptions Handling
– What is Exception?
– Handling an exception
– try….except…else
– try-finally clause
– Argument of an Exception
– Python Standard Exceptions
– Raising an exceptions
– User-Defined Exceptions - Python Regular Expressions
– What are regular expressions?
– The match Function
– The search Function
– Matching vs searching
– Search and Replace
– Extended Regular Expressions
– Wildcard - Python Multithreaded Programming
– What is multithreading?
– Starting a New Thread
– The Threading Module
– Synchronizing Threads
– Multithreaded Priority Queue
-Python Spreadsheet Interfaces
-Python XML interfaces - Using Databases in Python
– Python MySQL Database Access
– Install the MySQLdb and other Packages
– Create Database Connection
– CREATE, INSERT, READ, UPDATE and DELETE Operation
– DML and DDL Oepration with Databases
– Performing Transactions
– Handling Database Errors
– Web Scraping in Python
- Python For Data Analysis –
Numpy:
– Introduction to numpy
– Creating arrays
– Using arrays and Scalars
– Indexing Arrays
– Array Transposition
– Universal Array Function
– Array Processing
– Arrary Input and Output - Pandas:
– What is pandas?
– Where it is used?
– Series in pandas
– Index objects
– Reindex
– Drop Entry
– Selecting Entries
– Data Alignment
– Rank and Sort
– Summary Statics
– Missing Data
– Index Heirarchy
- Matplotlib: Python For Data Visualization
- Welcome to the Data Visualiztion Section
- Introduction to Matplotlib
- Django Web Framework in Python
- Introduction to Django and Full Stack Web Development
- Introduction to R
- Installation of R
- Types of Datatype
- Types of Variables
- Types of Operators
- Types of Loops
- Function Declaration
- R Data Interface
- R Charts and Graphs
- R statistics
- git
- nmpy
- scipy
- github
- matplotlib
- Pandas
- PyQT
- Theano
- Tkinter
- Scikit-learn
- NPL
- naive bayes
- Linear Regression
- K-nn
- C-nn
Frequently Asked Question on Data Science Course
Yes, We provide it For Groups and one-time fees payers.
Yes we are providing our own institution certificate.





























